AIの活用による生産性向上とリスク低減を両立するため、最低限の原則と禁止事項を定める。
基本方針 AIは目的に対して妥当で、かつリスクを許容できる場合に用いる。
全ての用途を一律で許可あるいは禁止するのではなく、用途やリスクに応じた取り扱いを行う。
AI利用の定義 本ポリシーにおけるAI利用とは、生成AI、機械学習モデル、推論API、外部AIサービスその他これに準ずる仕組みを業務やサービスに使うことを指す。
利用の原則 AIの出力は最終的に人間が持たねばならない。
出力の結果にだれも責任が持てない使い方をしてはならない。
リスクに応じた取り扱い AI利用は一律に扱わず、影響の大きさに応じて管理レベルを変える。
低リスク : 例) 公開情報を元にした下書き、要約、作業の軽微な補助中リスク : 例) 内部データを使う処理、対外文書の作成補助高リスク : 例) 決済、契約、個人情報、機密情報、影響が大きい意思決定影響が大きいものは、確認や記録の作業を強く行う。
リスクが高すぎて許容しがたい場合はAIを利用してはならない。
人による裁可 重要な判断は最後に人が確認し、裁可すること。
最初から全自動化ありきで設計せず、自動化してよい範囲、人が承認すべき範囲をリスクに応じて決定すること。
入力データの取り扱い 個人情報、機密情報、秘密情報をそのまま外部AIサービスに投入してはならない。
分析に用いる場合は事前に匿名化・マスキングし、流出しても問題ない状態まで無毒化すること。
学習利用、再利用は拒否すること。
誤りを織り込んだ出力の扱い AIの出力は常に誤りうる前提で扱う。
数値や契約、対外説明など重要情報は原典確認する コードや設定変更はレビューとテストを実行する 禁止事項 以下は禁止する。
法令、契約、社内規程に反する形でAIを利用すること 差別、不当な不利益、権利侵害を招く用途に使うこと商用利用・再利用が規約で禁止されている生成物やAIによるライセンス汚染が問題となるOSSの導入にも注意すること AIサービスに機密情報を入力すること 高リスク領域で人の確認を省くこと 記録と文書化 AI利用を業務に導入する場合は、黙って行うのではなく、明示的に証跡を残した上で行うこと。
保存形式やフォーマットは自由だが、下記が含まれるようにすること。
目的・用途と対象業務 利用開始日 利用者および責任者 利用するAIやサービスの名称 入力するデータの種類 想定リスク また見直し日、変更履歴、事故や問題も随時記録すること。
導入後の見直し AIの利用は継続的に見直すこと。
確認対象の例
利用のされかた 想定外の使われ方 コスト 外部サービスやモデルの仕様変更 法令、契約、社内ルールの変更 苦情、事故、ヒヤリハット レビュー頻度は影響に応じて決める。
高リスク: 必要時および定期的(例・四半期ごと) 中リスク: 変更時および定期的(例・半年ごと) 低リスク: 必要時 問題発生時の対応 AI利用で問題が起きた場合は、まず被害拡大を止め、その後に原因と再発防止を確認する。
対応の基本
利用停止 関係者への連絡、エスカレーション 影響範囲の確認 ログと証跡の保全 原因調査 再発防止 必要に応じて公表、報告、顧客対応 例外 業務上やむを得ず本ポリシーの例外運用が必要な場合は、記録を残し、かつ責任者の承認を得て行うこと。
前回は「仕様駆動開発が本命。でも自前実装は大変だから既存ソリューションのSpec Kitを利用することにした」と言うところまでお話しました。
早速Spec Kitの基本から見ていきます。
インストールと初期設定 uvxをインストールし、
curl -LsSf https://astral.sh/uv/install.sh | sh
spec-kitのインストールと初期設定。既存プロジェクトに導入するためここではプロジェクト指定を--hereとしています。
cd cognito-example/
uvx --from git+https://github.com/github/spec-kit.git specify init --here
下記のような状態になりました
~/repositories/cognito-example$ tree -a
.
├── .claude
│ └── commands
│ ├── constitution.md
│ ├── implement.md
│ ├── plan.md
│ ├── specify.md
│ └── tasks.md
├── .specify
│ ├── memory
│ │ └── constitution.md
│ ├── scripts
│ │ └── bash
│ │ ├── check-implementation-prerequisites.sh
│ │ ├── check-task-prerequisites.sh
│ │ ├── common.sh
│ │ ├── create-new-feature.sh
│ │ ├── get-feature-paths.sh
│ │ ├── setup-plan.sh
│ │ └── update-agent-context.sh
│ └── templates
│ ├── agent-file-template.md
│ ├── plan-template.md
│ ├── spec-template.md
│ └── tasks-template.md
└── cognito-example.code-workspace
基本のワークフロー Spec Kitのコマンドは2025/09/21時点で5つ。READMEからそのまま引き写しますが、下記のようになっています。
github/spec-kit が公開されました。AI駆動開発の本命であろう仕様駆動開発 の標準化に貢献するであろうこのプロジェクトにはとても注目しています。
論理的帰結としての仕様駆動開発 かつて私も仕様書を元にAIに作成させる方法を自著の同人誌 で提案したことがあります。やはり有利なのです。
まず大前提として、生成AIに作業をさせるためにはプロンプトが必要です。そのプロンプトは明確かつ必要十分の情報を保有していることが望ましいです。
そして開発プロジェクトにおいて「明確かつ必要十分の情報を保有している」プロンプトすなわちテキストとは、つまるところ仕様書です。仕様書とは設計やコーディングに必要な情報を明確かつ必要十分に記載したテキストなのですから。――常に実現できているとは限りませんが、目指してはいます。
である以上、
「いっそプロンプトとして仕様書を渡してしまえばいい 」
という発想に至るのは自然な帰結でしょう。
AIに渡すプロンプトを毎回作るのは大変ですし、再現性も低いという問題があります。これはバイブコーディングの泣き所でもあります。ですが仕様書を渡すスタイルなら何度でも書き終えた仕様書を渡せば済むわけです。再利用も簡単、追跡性もばっちりです。
Go言語を用いた開発プロジェクトに仕様駆動開発を導入することの課題とソリューションの登場 さて、前述の技術同人ではIaCを仕様駆動開発(と言う名前ではありませんでしたが)で実用にたるレベルで実行することができていました。これには下記の要因があります。
コードの規模が小さく単純 : Terraform用コードの生成であったためコードの規模がさほど大きくなく、また分岐等のロジックもごくわずかでしたベストプラクティスが豊富に用意されている : Terraformのコーディングは公式やAWSがベストプラクティスを用意しており、これをそのまま使うことで高品質の成果物を作成することが可能です。単独開発者 : 想定が私一人でも回る規模であったため、チーム内教育のことを考えなくて済みました。ところがこの成功体験をもとにGoプロジェクトで仕様駆動開発を実践しようとすると問題が生じました。上の条件の逆で、コードの規模が大きく複雑、取りうるアーキテクチャ・ライブラリ・ツールの数も多く、またチーム開発を想定する必要があったのです。これは必要なプロンプト(=ドキュメント)の量を増やし、開発体制の整備にかかる時間をIaCだけのケースよりはるかに大きなものとし、しかもチーム内教育への考慮まで要求されることとなりました。
これらの課題を地力で頑張って乗り切ることは、不可能ではないまでも多大な時間を要し、かつそこまでしても普及させられると思えず、ありていに言ってあまり割に合わない作業になりそうに思えました。
そのような状況で登場したのがKiroや今回のSpec Kit等、大手が提示するツールやプロジェクトです。まだ実験的な性格も強いようですが、おそらく開発体制の充実度合いや運用保守の強固さなどから、このタイプの提示する仕様駆動開発の採用が堅い選択になるのではないかと考えられます。
個別に最適化したほうがプロジェクトにフィットさせられるのでしょうが、現実的には、多くのプロジェクトでは人の入れ替わりや開発リソースの限界などの要因によってそう簡単ではありません。技術的な理想ではなくとも、運用や教育などの面まで含めた総合的判断においては、既存のソリューションを利用するほうがベストとなるケースが多いことでしょう。
かなり前置きが長くなりましたが、このようなわけで、独自開発ではなく既存プロジェクトに乗る方向で仕様駆動開発を試していきます。spec-kitです。
Goのフォーマッター「gofumpt」について解説します。
生成されたコードのチェックを自動化しよう 生成AIを使ってコーディングを自動化すると開発作業を大きく効率化することができます。しかし一方で、レビューの負担という新たな問題も生じています。
生成されたコードの品質は一般にまちまちで、差があるものです。これらを全て人力で修正していたのでは多大な時間がかかってしまい、せっかくAIで効率化した意味が減殺されてしまいます。チェックと修正自体も自動化しないといけないわけです。
コードスタイル(フォーマット)を機械的にチェック・修正できるフォーマッタは、生成AIが活躍するようになった現在においても大いに威力を発揮します。コードスタイルの些細な違いは動作に影響しませんが、可読性や保守性の観点からぜひ統一したいものです。
「フォーマッタが正しい」で割り切る簡便さ また開発プロジェクトからはまだまだ人が完全にいなくなったわけではありません。チーム開発となると複数名の開発者が参加します。このときコードスタイルをどのように決めるかは悩ましい課題となりがちです。
コードスタイルには個々の好みが出ます。括弧の位置や空行の入れ方程度のことですら個々の「こうしたい」があるのです。プロジェクトの都度合意を得るために何度もやりとりするのも大変です。それらをそれぞれが譲らず自分の好みで書き始めると収拾がつかなくなってしまいます(そしてそうなったのであろうコードを見ることも時折あります)。
その点「フォーマッタが正しい。以上」で決めてしまえば公正です。あらかじめ決まったルールを使えばいいため議論の必要もありません。しかも自動でコードスタイルを整えてくれるため、レビューの際に些細な改行の違いなどを見つけるために目を皿のようにする必要もなくなります。ただCIでフォーマッタの実行を保証すればよいだけになるのです。
標準を超えた整形ルールを提供するgofumpt そのようなわけで、Goの開発環境を整えるための施策の一つとして、フォーマッタ「gofumpt」を導入します。これはよりリッチになったgofmtと考えればよく、より厳格で豊富なフォーマットルールを適用します。例えば次のような処理をしてくれます。
括弧位置の統一 不要な空行の削除 コメントの余白の修正 詳細は公式 に紹介されているため、気になる方はそちらをご参照ください。
シンプルな導入手順と基本的な使い方 gofumptのインストールは以下のコマンドで行えます。ここでは簡単なlatestで紹介していますが、プロダクト用途なら意図せぬ動作変更がないようバージョンを指定したほうが安定します。
# プロダクト用途ならバージョン指定を推奨
go install mvdan.cc/gofumpt@latest
以下のコマンドでファイルをフォーマットできます。
# 単一ファイルのフォーマット
gofumpt -w main.go
# ディレクトリ内の全Goファイルをフォーマット
gofumpt -w .
ワークフローを記したファイルにコマンドを記載しておけば、AIエージェントがよろしくやってくれるはずです。ただし確実に行われることを保証するためCIにも組み込むほうがよいです。
実行例 どのようなフォーマットが行われるのかご紹介します。まずこちらはgofumptを適用する前のコード。
整形前のコード(sample_before.go):
package main
var V interface {
} = 3
type T struct {
}
func foo () (any , error ) {
return nil , nil
}
func bar () {
_ , err := foo ()
if err != nil {
return err
}
}
それが処理をかけるとこのようになりました。
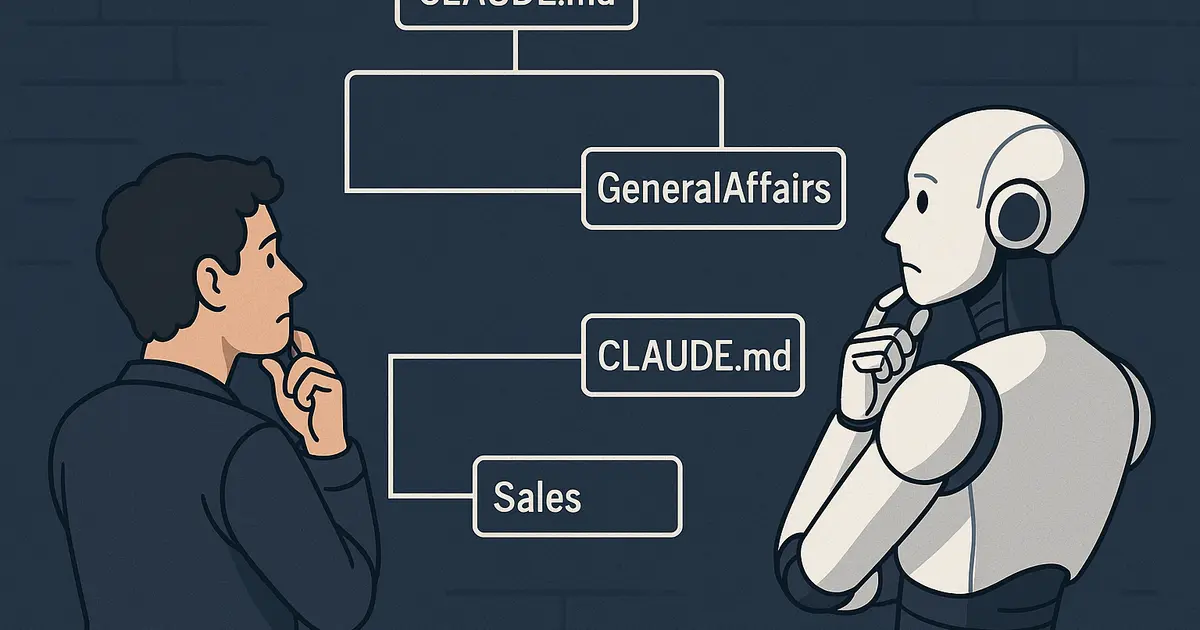
CLAUDE.mdをどこに配置すれば読まれるのか・読まれないのかを検証しました。
背景 Claude Codeの/initコマンドでCLAUDE.mdを作成すると、プロジェクト全体の要約を詰め込んだCLAUDE.mdがリポジトリルートに作成されます。しかし、このプロジェクト全体の要約は、個別の作業に必要ない情報も多く含まれます。例えばバックエンドのGoのテストを実行するコマンドの情報は、フロントエンドのコーディングをさせるのに必要ありません。
使わない情報を毎回読み込ませるのは無駄であり、各作業の精度低下や無駄なトークン費用の発生につながります。極力CLAUDE.mdは作業に最適化したものを使いたいところです。そのためにはCLAUDE.mdを細分化し、CLAUDE.mdが読まれる条件を把握した上で、それぞれうまく配置する必要があります。
REF: https://www.anthropic.com/engineering/claude-code-best-practices
CLAUDE.mdはただリポジトリルートに置くだけではない
リポジトリルートに配置したCLAUDE.md まず基本から。
リポジトリルートに配置したCLAUDE.mdは、サブディレクトリにいようと、同一階層に別のCLAUDE.mdがあろうと、読まれます。
~/repositories/ClaudeCodeTest$ cat CLAUDE.md
# CLAUDE.md
Reply with 'Awesome, Inc.' when asked for the company name.
~/repositories/ClaudeCodeTest$ echo "What is the company name?" | yolo -p
Awesome, Inc.
~/repositories/ClaudeCodeTest$ cd GeneralAffairs/GeneralServices/DocumentManagement/Digitization
~/repositories/ClaudeCodeTest/GeneralAffairs/GeneralServices/DocumentManagement/Digitization$ echo "What is the company name?" | yolo -p
Awesome, Inc.
~/repositories/ClaudeCodeTest/GeneralAffairs/GeneralServices/DocumentManagement/Digitization$ cd ../../../
~/repositories/ClaudeCodeTest/GeneralAffairs$ echo "What is the company name?" | yolo -p
Awesome, Inc.
~/repositories/ClaudeCodeTest/GeneralAffairs$ ls
CLAUDE.md GeneralServices
~/repositories/ClaudeCodeTest/GeneralAffairs$
※ yolo はClaude Codeのエイリアスです。.bashrcに右記のように設定しています。 alias yolo='claude --dangerously-skip-permissions'
セルフホストランナーのセットアップ 今回はWSL2上のUbuntuで実施。
ただしEC2等のクラウドのインスタンスのほうが安定するので、業務利用ならそちらを推奨します。
手順はこちらのまま。
https://docs.github.com/en/actions/hosting-your-own-runners/managing-self-hosted-runners/adding-self-hosted-runners
※ まだメモ書きです
🤖 コンテキスト引継ぎの重要ポイント 異なるディレクトリで会話した内容は、同じコンソールで作業しても–continueで引き継がれない 逆にプロセスが異なろうが、同じディレクトリで会話したら–continueで引き継がれる -> ディレクトリが同じかどうかがキモ
ブランチ作成の前提 親Issue:子Issue = 1: * ( 1つのイシューから0-*の子Issueが作られる。)Issue(親Issue、子Issueとも):PR = 1: * ( 1つのイシューから複数のPR(プルリクエスト)が作られる)PR:branch = 1:1 1つのPRに1つの作業ブランチbranch:agent = 1:1 1つのブランチに1つの担当エージェントIssue:agent = 1:1 1つのIssueに1つの担当エージェントまた、エージェントの役割の違いは、git worktree add を使って全部ブランチで表現する 。
従って、例えばこういうタスク分解がなされ、かつ、各Issueに管理エージェント、各PRにワーカーエージェントが対応してそれぞれ作業を進めることになった場合、
親Issue: API公開子Issue1: インフラ作るPR1: 要件定義 PR2: 設計 PR3: コーディング 子Issue2: コード作るPR4: 要件定義 PR5: 設計 PR6: コーディング 子Issue3: デプロイパイプライン作るPR7: 要件定義 PR8: 設計 PR9: コーディング エージェント数と同じだけ必要になるので、13ブランチ必要 になる。
ブランチ名 暫定的に
Issueはfeature/<parent_issue_id>とスラッシュ区切りで表す。ただし親Issueがある場合はfeature/<parent_issue_id>/<child_issue_id>とする。なお直上の親Issueだけ書き、その上のIssue以降を書いてはならない。 PRはfeature/<issue_id>/<child_issue_id>/<work_name>のようにIssueのブランチ名に/文字列を加えて表す とする。またそれとは別にmain(本番用)やdevelopment(開発環境用)、hotfix/X(超急ぎのバグフィックス)などがありえるが、その辺は各流儀に合わせる方向で。
例えばこのようになる。
feature/9 # 親Issue: API公開
feature/9/10 # 子Issue1: インフラ作る
feature/9/10/requirements # 要件定義
feature/9/10/design # 設計
feature/9/10/implementation # 実装
feature/9/11 # 子Issue2: コード作る
feature/9/11/requirements
feature/9/11/design
feature/9/11/implementation
feature/9/12 # 子Issue3: デプロイパイプライン作る
feature/9/12/requirements
feature/9/12/design
feature/9/12/implementation
マージ戦略 紐づくブランチにマージする。いきなりmainやdevelopmentに直マージはしない。
⚠️ 注意: これは実験段階のメモです。実際の検証はまだ行っていません。
背景・課題 現在の問題 Claude Codeを使用してローカルで開発作業を行う際、以下の課題が発生している:
Claude CodeがPRを作成してくれるが、なぜその実装をしたのか の背景情報がGitHub上に残らない 作業過程での判断理由や試行錯誤がローカルにしか保存されず、ほかのメンバー(後日すべてを忘れた自分自身含む)が背景を理解できない 技術的な背景 Claude Codeの会話履歴は ~/.claude/projects/**/*.jsonl にローカル保存される GitHub上のIssueやPRには、Claude Codeの思考過程や判断理由が記録されない 既存のClaude Code GitHub Actionsは、GitHub Actions上での実行を前提としており、ローカル実行の履歴は対象外 調査結果 既存事例の探索 GitHub OpsでClaude Codeの行動履歴をIssueに集めた事例を調査したが、以下のような状況だった:
アイディア headless mode : claude -p "<prompt>" --output-format stream-json でJSON形式の出力が可能GitHub CLI : gh でIssueにコメントを投稿できる制約・限界 claude-code-base-actionはGitHub Actions上での実行が前提で、ローカル実行履歴は対象外 ローカル実行履歴をGitHub Issueに自動投稿する確立された事例は発見できず この分野はまだ未開拓領域と判断される 解決策(仮説) 提案するワークフロー 以下のシンプルなアプローチで課題解決を図る:
Issue作成 : GitHub上で作業内容のIssueを事前に作成Claude Code実行 : headless modeでClaude Codeに明示的指示claude -p "Issue #123を見て実装しろ。作業過程と判断理由をそのIssueにコメントとして投稿しろ" --output-format stream-json
自動記録 : Claude CodeがGitHub CLIを使ってIssue commentに作業履歴を投稿PR作成 : 実装完了後、PRも作成この方法の利点 シンプル : 既存機能のみで実現可能、複雑な追加開発不要トレーサブル : Issue上に「なぜこの実装をしたのか」が記録される想定される技術要素 Claude Code headless mode (--output-format stream-json) GitHub CLI (gh issue comment) Issue事前作成によるコンテキスト提供 次のステップ 検証予定項目 Claude CodeがGitHub CLI経由でIssue commentを投稿できるかの確認 headless modeでの指示内容の最適化 作業過程記録の品質評価 期待される効果 PRレビュー時の文脈理解向上 コードメンテナンス時の背景情報活用 Claude Code利用時のトレーサビリティ確保 チーム開発における透明性向上
すべての許可プロンプトを一括でスキップ 大変効率的ですが、大変危険なので利用は自己責任でお願いいたします。
claude --dangerously-skip-permissions
CLIのオプション一覧 公式ドキュメントはこちら
https://docs.anthropic.com/ja/docs/claude-code/cli-usage
nwiizo=sanの設定例 大変参考になるので見るべし
https://gist.github.com/nwiizo/8b7eb992875fc67a89368062d42d501e
トークン数を挙げるためのワード https://simonwillison.net/2025/Apr/19/claude-code-best-practices/
下記でよりしっかり考えさせることができる(こともある)とのうわさ。
日本語だと
なのだとか。
https://x.com/millionbiz_/status/1929591134080454665
powershellでモデル一覧を表示 curl.exe "https://api.anthropic.com/v1/models" `
-H "x-api-key: $Env:ANTHROPIC_API_KEY" `
-H "anthropic-version: 2023-06-01"
AI連携エディタは開発作業を効率化できる便利なツールですが、機密情報をうっかり渡してしまわないよう注意する必要があります。AI連携エディタが利用したデータは外部のAIサービスへ送信されているためです。「AI連携機能を利用する」=「外部に情報を送信する」なのです。
機密性の低い情報に対してまで必要以上に警戒すべきとは言えません。それによって効率性を損なうことは別の問題を生じます。また現実問題として外部送信程度なら許容できるケースも多くあることでしょう。しかしAPIキーや顧客の個人情報などの機密性が極めて高い情報については話が別です。このような情報は送信してしまうだけで問題、まして悪用されたとなれば大問題です。ちゃんと外部AIに学習させない設定を有効化していれば外部AIに送った情報は流用されないはずですが、完璧とは限りません。AI連携エディタのCursorの開発元自身、シビアな用途で利用する際は注意するよう呼びかけています。
While we have several large organizations already trusting Cursor, please note that we are still in the journey of growing our product and improving our security posture. If you’re working in a highly sensitive environment, you should be careful when using Cursor (or any other AI tool).https://www.cursor.com/ja/security )
エディタ内からAIに問い合わせなければ大丈夫とも言いきれません。AI連携エディタはバックグラウンドでもAIを利用しており、気付かないうちに情報が送信されうるためです。むしろ機密情報の書かれた設定ファイルを開くだけでもリスキーと考えるべきです。つまるところ、極めて厳しいセキュリティが必要とされる情報を取り扱っているなら、それらにアクセス自体できないようAI連携エディタを物理的あるいは論理的にシャットアウトするのが一番です。
AIは便利だが機密情報まで送信すべきでない
専用ユーザーを作ろう Windows11の場合、AI連携エディタを利用して開発を行うための専用ユーザーを作成することで、外部に送信される可能性のある情報をしっかり管理できます。この専用ユーザーにはあらかじめ公開可能なプロジェクトのみを渡し、機密情報が保存されたディレクトリにアクセスできないようにしておきます。うっかりミスで機密情報をAI連携エディタに渡してしまう事態を
Powershellで実施する場合はこのようなコードになります。
# AI連携エディタ用ユーザーの作成
#
# [Usage]
# 1. 管理者権限で PowerShell を開きます。
# 2. スクリプトを一時的に実行できるようにします。(e.g. `Set-ExecutionPolicy RemoteSigned -Scope Process`)
# 3. スクリプトを保存したディレクトリに移動し、実行します。 (e.g. `.\create-ai-user.ps1 -Username AIUser -Password pass_is_here`)
param (
[Parameter(Mandatory = $true)]
[string ]$Username,
[Parameter(Mandatory = $true)]
[string ]$Password
)
$SecurePassword = ConvertTo-SecureString $Password -AsPlainText -Force
New-LocalUser -Name $Username -Password $SecurePassword -FullName " $Username" -Description "AI editor user (developer)"
if (-not $Username) {
Write-Error "Fail to create user: $Username"
exit 1
}
Add-LocalGroupMember -Group "Users" -Member $Username
管理者ユーザーではなくローカルユーザーとして作成します。その上で機密情報を取り扱うディレクトリやファイルのアクセス権を拒否し、アクセス自体不可能にします。